Infrastructure
Gurmukhi Unicode
Explore how Punjabi lives natively inside modern operating systems. Learn the hidden digital code-point grid that renders stacking vowels, accents, and sub-joined clusters across screens.
System Architecture
A global standard map ensuring that Punjabi displays flawlessly on any device across earth.
Universal Allocated Block
U+0A00 – U+0A7F
Total Character Slots
128 Blocks
Layering Modifier Code
U+0A4D (Halant)
Cross-Platform Sync
100% Native
New to typographical mechanics? Before analyzing how characters map to hex slots below, discover how rows are physically grouped by throat and lip articulation in our Gurmukhi Alphabet Guide →
How Gurmukhi Lives Inside Your Devices
Every time you type a character on a smartphone, send a text, or check a watch face, your device executes a hidden translation sequence. Computers do not actually understand letters or geometric shapes; they only understand numbers.
Gurmukhi Unicode Hex Registry
Browse the official, verified hexadecimal addresses assigned to each structural building block of the script.
Core Alphabet (ਮੂਲ ਵਰਣਮਾਲਾ)
The primary foundational building blocks of Gurmukhi, including independent vowel carriers and the standard consonant matrix.
U+0A05
ਐੜਾ / Aira
U+0A06
ਆ / Aa
U+0A07
ਇ / I
U+0A08
ਈ / Ee
U+0A09
ਉ / U
U+0A0A
ਊ / Oo
U+0A0F
ਏ / Ae
U+0A10
ਐ / Aai
U+0A13
ਓ / O
U+0A14
ਔ / Au
U+0A73
ਊੜਾ / Ura
U+0A72
ਈੜੀ / Iri
U+0A38
ਸੱਸਾ / Sassa
U+0A39
ਹਾਹਾ / Haha
U+0A15
ਕੱਕਾ / Kakka
U+0A16
ਖੱਖਾ / Khakha
U+0A17
ਗੱਗਾ / Gagga
U+0A18
ਘੱਘਾ / Ghagha
U+0A19
ਙੰਙਾ / Nganga
U+0A1A
ਚੱਚਾ / Chacha
U+0A1B
ਛੱਛਾ / Chhachha
U+0A1C
ਜੱਜਾ / Jajja
U+0A1D
ਝੱਝਾ / Jhajha
U+0A1E
ਞੰਞਾ / Nyanya
U+0A1F
ਟੈਂਕਾ / Tainka
U+0A20
ਠੱਠਾ / Thatha
U+0A21
ਡੱਡਾ / Dadda
U+0A22
ਢੱਢਾ / Dhadha
U+0A23
ਣਾਣਾ / Nana
U+0A24
ਤੱਤਾ / Tatta
U+0A25
ਥੱਥਾ / Thatha
U+0A26
ਦੱਦਾ / Dadda
U+0A27
ਧੱਧਾ / Dhadha
U+0A28
ਨੱਨਾ / Nanna
U+0A2A
ਪੱਪਾ / Pappa
U+0A2B
ਫੱਫਾ / Phapha
U+0A2C
ਬੱਬਾ / Babba
U+0A2D
ਭੱਭਾ / Bhabha
U+0A2E
ਮੰਮਾ / Mamma
U+0A2F
ਯੱਯਾ / Yayya
U+0A30
ਰਾਰਾ / Rara
U+0A32
ਲੱਲਾ / Lalla
U+0A35
ਵਾਵਾ / Vava
U+0A5C
ੜਾੜਾ / Rhara
Modified Alphabet (ਪੈਰ ਬਿੰਦੀ)
Six specialized additional letters featuring a sub-dot mechanism to capture loan vocabularies with strict phonetic tracking.
U+0A36
ਸੱਸੇ ਪੈਰ ਬਿੰਦੀ / Sasse Pair Bindi
U+0A59
ਖੱਖੇ ਪੈਰ ਬਿੰਦੀ / Khakhay Pair Bindi
U+0A5A
ਗੱਗੇ ਪੈਰ ਬਿੰਦੀ / Gaggay Pair Bindi
U+0A5B
ਜੱਜੇ ਪੈਰ ਬਿੰਦੀ / Jajjay Pair Bindi
U+0A5E
ਫੱਫੇ ਪੈਰ ਬਿੰਦੀ / Faffay Pair Bindi
U+0A33
ਲੱਲੇ ਪੈਰ ਬਿੰਦੀ / Lallay Pair Bindi
Vowels & Matras (ਲਗਾਂ ਮਾਤਰਾਂ)
Dependent phonetic signs assigned to override or transform the script's foundational inherent sound levels.
Inherent (No Sign)
ਮੁਕਤਾ / Mukta
U+0A3E
ਕੰਨਾ / Kanna
U+0A3F
ਸਿਹਾਰੀ / Sihari
U+0A40
ਬਿਹਾਰੀ / Bihari
U+0A41
ਔਂਕੜ / Aunkar
U+0A42
ਦੁਲੈਂਕੜ / Dulankar
U+0A47
ਲਾਂਵ / Lavan
U+0A48
ਦੁਲਾਵਾਂ / Dulavan
U+0A4B
ਹੋੜਾ / Hora
U+0A4C
ਕਨੌੜਾ / Kanaura
Modifiers (ਲਗਾਖਰ)
Auxiliary character structures tasked with handling double-stress sounds and nasal vocal accents.
U+0A02
ਬਿੰਦੀ / Bindi
U+0A70
ਟਿੱਪੀ / Tippi
U+0A71
ਅੱਧਕ / Addhak
Sub-joined / Pairin (ਪੈਰ ਵਿਚ ਅੱਖਰ)
Specialized root letters clustered directly underneath standard symbols to change aspiration and blending configurations.
U+0A4D + U+0A39
ਪੈਰ ਵਿਚ ਹਾਹਾ / Pair ch Haha
U+0A4D + U+0A30
ਪੈਰ ਵਿਚ ਰਾਰਾ / Pair ch Rara
U+0A4D + U+0A35
ਪੈਰ ਵਿਚ ਵਾਵਾ / Pair ch Vava
Numerals (ਅੰਕ)
The traditional decimal digit systems explicitly mapped inside the official Unicode blocks.
U+0A66
ਸਿਫ਼ਰ / Sifar
U+0A67
ਇੱਕ / Ik
U+0A68
ਦੋ / Do
U+0A69
ਤਿੰਨ / Tinn
U+0A6A
ਚਾਰ / Chaar
U+0A6B
ਪੰਜ / Panj
U+0A6C
ਛੇ / Chhe
U+0A6D
ਸੱਤ / Sat
U+0A6E
ਅੱਠ / Ath
U+0A6F
ਨੌ / Nau
Special Marks & Controls (ਖ਼ਾਸ ਚਿੰਨ੍ਹ)
Crucial typographical controllers, sign bounds, and traditional sacred glyph representations.
U+0A74
ਇੱਕ ਓਅੰਕਾਰ / Ek Onkar
U+0A3C
ਪੈਰ ਬਿੰਦੀ ਚਿੰਨ੍ਹ / Nukta Sign
U+0A4D
ਹਲੰਤ / Virama (Halant)
U+0A75
ਯਕਾਸ਼ / Yakash (Subjoined Yakash)
U+0A51
ਉਡਾਤ / Udaat (High Tone Accent)
Anatomy of a Block
The Gurmukhi registry range isolates functional categories into clean tiers. Rather than sorting randomly, strings are parsed systematically to coordinate characters alongside modifier points.
Software stacks multiple overlapping character addresses fluidly onto a shared coordinate base layer.
Foundation Layers (Base Consonants)
Permanent code locations assigned to the foundational 35 characters. When a device reads a value like U+0A15, it renders a clean 'Kakka' (ਕ) shape regardless of whether it is an iOS lock screen or an Android ticker system.
Attachment Layers (Dependent Matras)
The non-spacing combining characters. These codes tell your phone's graphics chip to physically append vowel symbols above, below, or to the flank of a base consonant carrier instead of spacing them sequentially on a flat line.
Modifier Layers (Nasal Control)
Special hex registers allocated exclusively for Bindis, Tippis, and Adhaks. They modify air flow accent parameters dynamically over the base script geometry.
The Sub-Joined Glue Code
An invisible layout controller (U+0A4D) that strips away inherent resting vowels. It acts like digital magnetism, instructing font engines to stack trailing letters directly beneath a preceding character base.
Byte Composition Lab
See how independent text code positions seamlessly merge step-by-step behind single complete words.
Samaa (Time)
Hex Address Mapping Stack
Infrastructure Node: The dynamic Bindi at the end requires character U+0A02 to layer seamlessly onto the carrier system without causing text container clipping.
Preet (Love)
Hex Address Mapping Stack
Infrastructure Node: Utilizes the layout glue code (U+0A4D) to instantly force the 'Rara' into a sub-foot sub-joined cluster configuration underneath the 'Pappa' root frame.
From Hex Points to Practical Application
Unicode encoding bridges raw architectural code blocks and high-fidelity consumer software. By implementing exact hex allocations alongside smart text layout engines, we are building systems that process native script elements precisely across critical device layers.
Production Implementations
A functional production use-case utilizing exact Gurmukhi Unicode layers to drive localized timekeeping engines and complex Nanakshahi calendar mathematics.
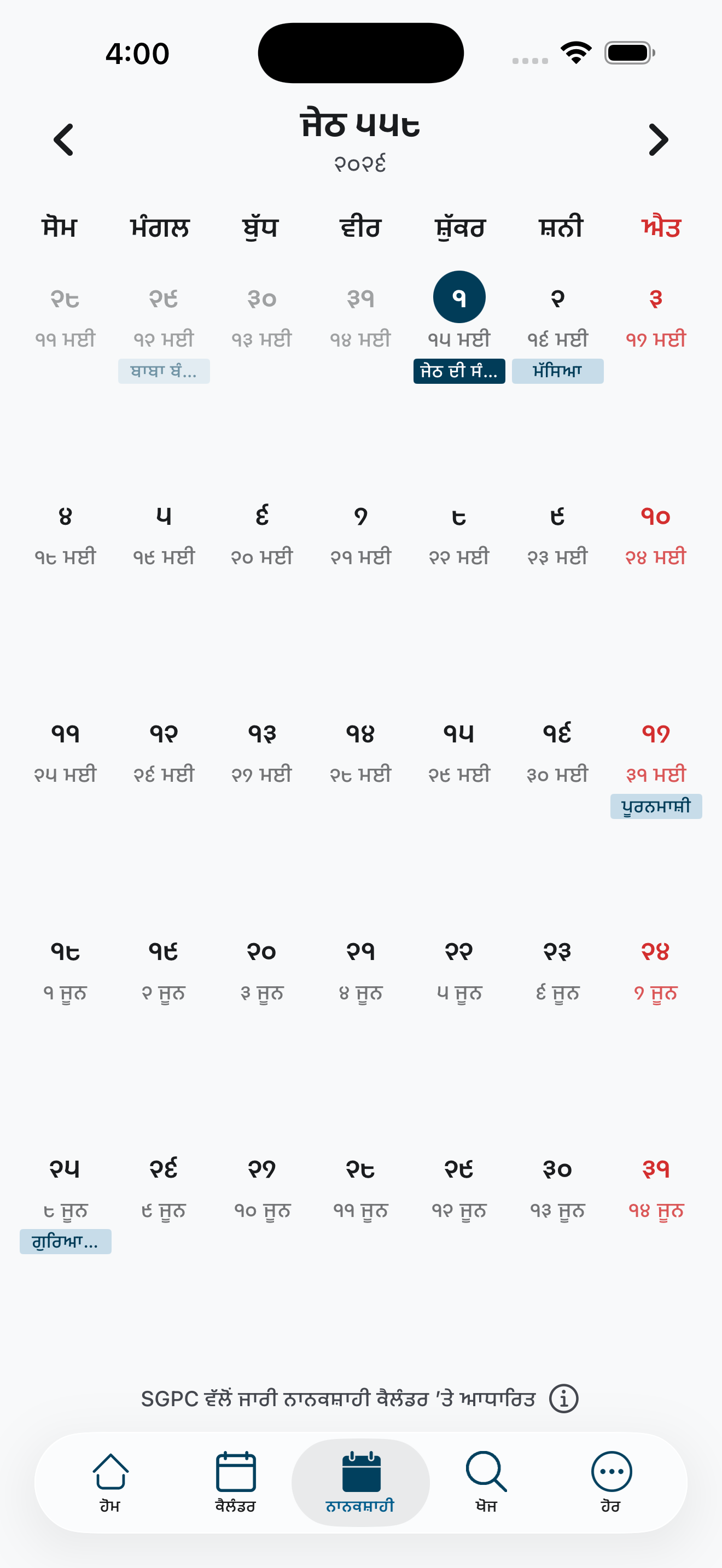
Learner FAQs
Clear answers to simple questions people ask when exploring Punjabi numbers for the first time.
What is the official Unicode character range for the Gurmukhi script?
The official Unicode block allocated for Gurmukhi is U+0A00 to U+0A7F. This compact 128-byte range contains all foundational letters, dependent vowel signs (matras), lagakhar modifiers (Bindi, Tippi, Addhak), unique Punjabi numerals (0-9), and structural system controls like the Virama (Halant).
Why does Gurmukhi text length show up incorrectly in standard JavaScript string.length properties?
JavaScript calculates string length based on 16-bit UTF-16 code units rather than visual glyphs. Because complex characters like 'ਕੀ' are composed of a base consonant (U+0A15) plus a dependent matra (U+0A40), string length operations return 2 instead of 1. Developers should utilize the JavaScript Intl.Segmenter API with a grapheme granularity option to accurately target layout calculations in production environments.
How do you fix Gurmukhi vowel diacritics and matras clipping or overlapping in Tailwind CSS or React Native?
Clipping usually happens because line-height layout constraints are too tight, cutting off tall vertical elements like the Sihari, Bihari, or Bindis. To ensure complex subjoined loops render cleanly, adjust line-height properties dynamically, implement uniform padding configurations, and verify the font includes cross-platform GPOS (Glyph Positioning) tables.
What is the difference between Bindi (U+0A02) and Tippi (U+0A70) when encoding nasal sounds?
While both signs encode a nasalized sound component, their deployment rules are strictly dependent on the accompanying vowel diacritic. Tippi (U+0A70) is structurally paired with Mukta, Sihari, Aunkar, and Dulankar vowel marks. Bindi (U+0A02) handles all remaining open vowel configurations including Kanna, Bihari, Lavan, Dulavan, Hora, and Kanaura.
Why do some older Punjabi text documents look corrupted or display random English letters when copied?
Older legacy files used non-standard ASCII 'font-mapping' techniques where Punjabi glyphs merely hijacked English keyboard layout structures. When shared into modern standards-compliant layout spaces, the configuration fails. These strings must be converted using code array map algorithms translating legacy configurations into standard clean Unicode.
Explore The Gurmukhi Project
Discover apps, watch faces, and digital tools built to make Gurmukhi more accessible across modern devices.